Monitoring Feedback as You Speak: How Diva Contributes to Explaining a Part of the Problem of Cluttering, and to Developing a Therapy Plan
 |
About the presenter: Margaret Leahy is Director of the School of Clinical Speech & Language Studies, Trinity College, Dublin, Ireland. She has been working as a researcher/practitioner in the field of stuttering/fluency for 25 years, and for most of that time has also been involved in student therapist education. Since the 1980's, she has presented papers and workshops on PCT and therapy, and has published a number of these. She has also done research on the 'stutterer' stereotype, particularly with regard to student stereotyping. She been involved with the IFA since its foundation, and is a past President of that organisation. |
Monitoring feedback as you speak: how DIVA contributes to explaining a part of the problem of cluttering, and to developing a therapy plan.
by Margaret Leahy
from IRELAND
There is a wide range of elements or symptoms attributed to the problem that is called cluttering. Recently, with increased knowledge and research, along with the establishment of the International Cluttering Association, we are in a better position to begin to disentangle some of the complexity of cluttering, to develop awareness in the public as well as the therapy domain, and to shed light on managing the problem.
This brief article focuses on one important element of cluttering, the lack of monitoring feedback as you speak that may explain a lack of awareness of having a problem, as well as the mismatch between what one believes is being said and cluttered speech. In selecting this focus, the elements of neurological and motor control explanations, along with linguistic and non-speech characteristics are not in any sense undermined. Rather my aim is to complement these explanations and components, and to link the current model of DIVA - Directions into Velocities of Articulators (Guenther, 2006) - to the management of cluttering.
In a recent Blog on AIS (American Institute of Stuttering; February 15th 2010), Craig chats with one of his therapy team, Chamonix. Craig is 'someone who clutters and stutters sometimes'. He has completed an intensive course, and now speaks with a high degree of fluency, obvious confidence in front of a camera, and well-polished non-verbal behaviours (including smiling when introduced to the unseen audience; head nods in agreement; appropriate gaze etc).
Craig mentions in the interview that when listening to himself on audio-tape, he dissociates what he hears from 'what it sounds like in my head'. This particular point raises the question: What is he hearing 'in his head' when he talked? That in turn raises another question: What is he not hearing well enough that he cannot discern the problem in his own speech when he is cluttering?
The model of clearly articulated, intelligible speech that is readily understood seems to be in place within Craig's speech-language system: what he is saying makes sense to himself, and sounds to him as if it is clearly articulated. But what comes out of his mouth when he is talking becomes cluttering, so is less intelligible, with irregular or fast rate (along with possible use of intonation patterns that do not match what he is saying in grammatical or semantic terms), with inappropriate degrees of coarticulation, especially in multisyllabic words (cf St. Louis, Myers, Bakker, Raphael; 2007). Craig refers to the elements or rate and coarticulation as 'rapid speech to the point where you put all of your words kind of syllables of the same word in too quickly to make sense sometimes'. He also refers to when he was younger, saying that he 'really had no idea I was doing it for the most part...'.
In these explanations, Craig pinpoints some characteristics that may be core to cluttering: the ability to monitor feedback of his speech accurately. Such monitoring involves the speaker paying attention to the minutia of speech planning and speech production to check that what is said is what was intended, that it sounds right, and that it makes sense in the context. This necessarily involves paying attention to a range of steps of stages in the process that rely on neurological impulses that control muscle movements to plan and to produce meaningful speech. How do we do this?
Typically, when children reach the age of 5 years, they have achieved the facility of articulating words, and putting them in order to get complex messages across to listeners, and they seem to manage this without paying conscious attention to what is going on. However, earlier there is a phase of development that requires monitoring of feedback to achieve this level of expertise. A recent model, entitled DIVA will help to explain what underlies the production of appropriate speech sounds.
DIVA is short for Directions into Velocities of Articulators -- a system developed by Frank Guenther and colleagues in their speech laboratory at Boston University (http://speechlab.bu.edu/diva.php). In the DIVA model, Guenther (2006) explains the main components in the Figure 1 below:
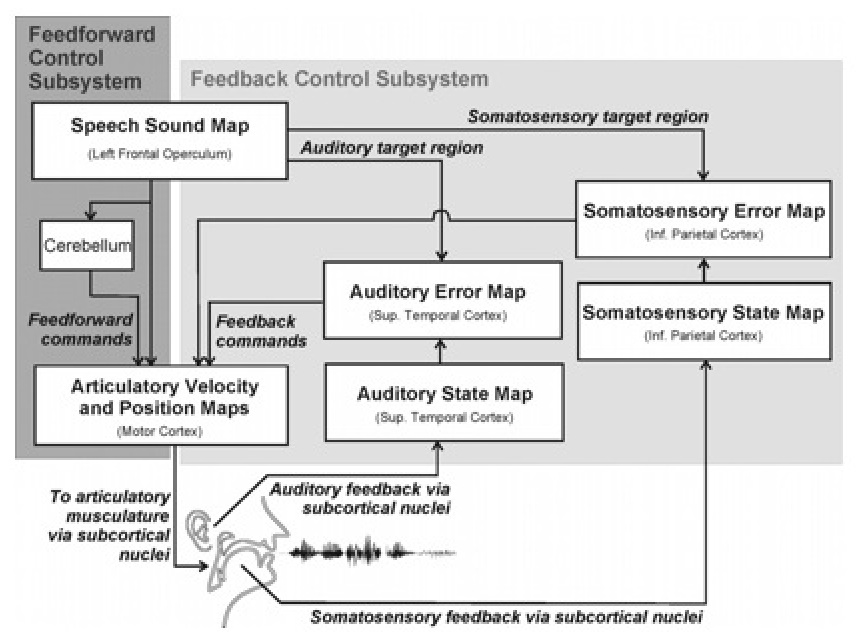
Fig. 1 Directions into Velocities of Articulators: the (DIVA) model.
Each box in the diagram maps the neurons in the brain that are activated in the process of producing speech sound or syllables. The production of a speech sound in the DIVA model starts with activation in Broca's area of the frontal cortex of the brain (left frontal operculum in Fig 1). This leads to motor commands that arrive via two control subsystems: a feedforward control subsystem and a feedback control subsystem. The feedback control subsystem has both auditory feedback and a somatosensory (bodily tactile, muscle-positioning and sensory) feedback control subsystem. These three main types of information (motor, auditory, somatosensory) are represented in the temporal, parietal, and frontal lobes of the brain's cortex. These regions of the cortex and their interconnections, along with subcortical structures (cerebellum, basal ganglia, and brain stem) are the basis of the neural control system for speech production.
Guenther explains that as infants, accurate feedforward commands for all speech sounds are not available. Practice is part of the process of achieving accuracy for the sounds of a particular language, and following extensive practice with appropriate auditory feedback can feedforward commands be tuned. "In the DIVA model, feedforward commands for a syllable are tuned on each production attempt. In the first attempt to produce a new sound, the model relies heavily on auditory feedback control to produce the sound since its feedforward commands are inaccurate, thus resulting in auditory errors that activate the feedback control subsystem. The corrective commands issued by the auditory feedback control subsystem during the current attempt to produce the sound become stored in the feedforward command for use on the next attempt." (Guenther, 2006: 360) Each attempt to produce a particular speech sound results in improved feedforward command that needs less auditory supervision for correction, until the feedforward command is capable of independently producing the sound without any auditory error.
Guenther concludes this part of the explanation thus: "At this point, the auditory feedback subsystem no longer contributes to production unless speech is perturbed in some way or the sizes or shapes of the articulators change. As the speech articulators grow, the auditory feedback control subsystem continues to provide corrective commands that are subsumed into the feedforward controller." Thus, the feedforward controller is allowed to stay properly tuned despite dramatic changes in the sizes and shapes of the speech articulators throughout a lifetime. (p. 360).
Applying some of the elements of the DIVA model to Craig's explanation of cluttering, we can suggest that Craig's feedforward mechanism may be relatively intact, so that he is aware of the appropriate sounds to produce that will make sense and get his message across. However, if the feedback system that includes both auditory and somatosensory has not been providing the appropriate feedback, then the feedforward mechanism may be 'faulty' in that it may not be 'properly tuned'. Similarly, the auditory and somatosensory feedback systems may not be fully functioning, explaining why Craig was not aware of the speech errors he was making, and that he continued to produce cluttered speech.
This kind of explanation can lead to therapy options that focus on improving monitoring feedback, by improving feedforward and feedback mechanisms. Such therapy would incorporate an increase in monitoring feedback through increasing awareness of how speech sounds are produced. The following steps are suggested:
- increase awareness, contrast and compare, practice, record, listen to and evaluate the differences in manner and place of articulation of sounds and syllables;
- increase awareness, practice, record, listen to and evaluate intonation and stress patterns of sounds in words;
- reduce the rate at which syllables and words are produced; record, practice, listen to and evaluate how clarity in articulation changes (improves) as rate of speech is reduced.
These steps can be further developed in activities in small groups, where each member monitors each other, imitating, contrasting and comparing productions, providing feedback, and monitoring feedback as one speaks.
Continually monitoring feedback in one's speech is a difficult task, but its rewards may be great: Craig observes that 'exaggerating syllables' was something that was hard to do... but he makes the suggestion that 'all you have to do is to practice... easier said than done, but it can be done'. His success may be based on a wide range of therapy factors, but monitoring feedback is one important facet of the whole
REFLECTION: In applying DIVA to Cluttering, there was an echo in my mind of Charles Van Riper's (1971) explanation of competing feedback systems as a possible explanation for the onset of stuttering (he even applied the term 'somesthesia' to represent the touch-kinesthesia-proprioception feedback elements (p. 393-395) similar to what Guenther calls somatosensory feedback). The DIVA model as applied here is an effort to take just some aspects of what is emerging in the scientific study of speech, try to explain and apply these to help understand one aspect of cluttering.
References:
Blog on AIS (American Institute of Stuttering); February 15th 2010.
Guenther, F. Cortical interactions underlying the production of speech sounds. Journal of Communication Disorders 39 (2006) 350-365.
St. Louis, K. O., Myers, F. M., Bakker, K., & Raphael, L. J. (2007). Understanding and treating cluttering. In R. F. Curlee & E. G. Conture (Eds.) Stuttering and related disorders of fluency, 3rd ed. NY: Thieme
Van Riper, C. The Nature of Stuttering. Englewood Cliffs: Prentice-Hall. 1971.
SUBMITTED: March 11, 2010